Introducing IPFS
The Interplanetary File System (IPFS) is a peer-to-peer distributed file system that seeks to connect all computing devices with the same system of files, allowing for a fully decentralized data network.
Core Functionality
IPFS serves 3 major roles: file management, file storage and file versioning. The IPFS protocol aims to host and distribute massive datasets (up to 1000 terabytes), allows for versioning and linking of these datasets, as well as computing on datasets across organizations. The network plans for high-volume, high-definition, on-demand, real-time media streams, while also preventing the accidental disappearance of important files.
Current Issue
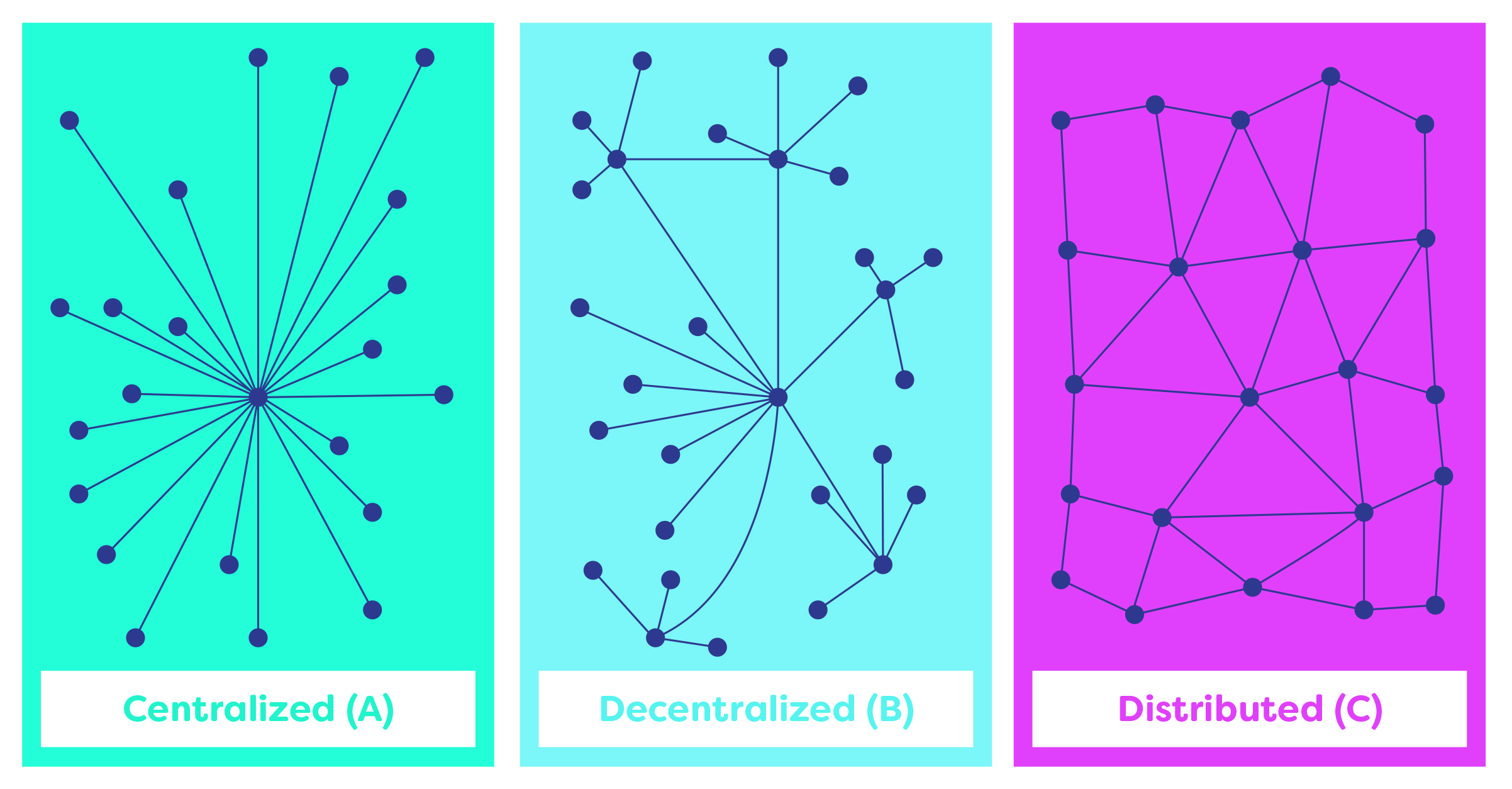
From its inception in 1991, the Hypertext Transfer Protocol (HTTP) has unified the entire world into a single global information protocol, standardizing how we distribute and present information to each other. However, in the most recent decade as decentralized technologies have come into existence, the current file sharing/information protocols have been unable to fully support these new distributed platforms. In order for a globally decentralized ecosystem to thrive, it is critical that a distributed file sharing protocol system be used.
BitTorrent and BitSwap
If you’ve ever heard of µTorrent or other torrenting services, the concept of distributed storage may be familiar. Rather than a central server hosting a file for download, the file is broken into many segments which are stored on many servers throughout the network. These files can be “seeded” by hosts, allowing users to download a file from multiple sources. Once downloaded, those same users can then go on to seed that file for others.
As described by IPFS, ‘Bitswap is a core module of IPFS for exchanging blocks of data. It directs the requesting and sending of blocks to and from other peers in the network. Bitswap is a message-based protocol where all messages contain want-lists or blocks.’
To learn more about how this works please refer to the IPFS documentation or ipfs.io
Content Addressing and File Versioning
In standard HTTP the location of a file is determined by its address, assigned by the owner of the file. In IPFS, the address of a file is determined by the file’s contents and not by any single entity. Content addressing is accomplished by cryptographically hashing the contents and using that hash as the address. Instead of referring to objects (pics, articles, videos) per server they are stored on, IPFS refers to everything by the hash of the file – derived from its contents.
Whether containing a single letter or an entire book, once a file goes through a hash algorithm it will have a unique hash address of 46 characters (in IPFS always beginning with “Qm”). Any duplication of that information will result in the same hash, thus resolving deduplication. However if the contents of the file are modified in the slightest, a completely different looking 46-character hash address will be generated. Through this system every version of a file will have a unique hash and therefore be permanently stored throughout the network.
IPFS & HTTP
What’s wrong with HTTP? Simply put, there are too many single points of failure. Servers can be shutdown, modified or blocked. These issues are commonly due to servers crashing without proper backups, domain ownership changing hands, companies going out of business or government interference. All of these problems lead to permanently losing the ability to access the affected domains and resulting information.
How is IPFS different? With HTTP you search for locations, with IPFS you search for content.
When you ask the IPFS network for a specific hash, it efficiently finds the nodes that have the data, retrieves it, and verifies it is the correct data using the hash. Multiple copies of data are stored on many nodes throughout the network, and are all easily retrievable based on their hash address created from the underlying content.
The distributed web will quickly become the fastest, most available and largest store of data on planet earth. And no one will have the ability to destroy information by shutting it down.
Use Cases with IPFS
IPFS has the ability to not only improve the World Wide Web, but to usher in a new era of decentralized applications built upon this distributed network. There are several professions that will see immediate advantages. Archivists, researchers and blockchain developers will be able to store, organize, distribute and work with incredibly large datasets. Service providers and content creators will be able to deliver vast amount of information at a fraction of the traditional cost while increasing security, and the developing world will have resilient access to data, independent of low latency or connectivity to the network.
How district0x uses IPFS
IPFS plays a core role for district0x in 2 ways. It allows us to serve user uploaded files within districts and to serve up our website source code displaying the corresponding web page.
While these may seem simple, the importance of distribution and immutability of district0x files on the backend cannot be overstated. IPFS allows for district0x to guarantee critical files are stored on our designated servers through pinning. Pinning is a process by which a node stores a particular object on the node’s internal storage, thus ensuring that object’s survival.
These files are also backed up by IPFS throughout the network on other nodes. This ensures that if any of our servers were to go down, in the event of natural disasters for instance, we (and anyone else) would be able to immediately retrieve the district0x core files from the IPFS network. This is critical in bringing district0x one step closer to operating as a truly open source, decentralized platform. Without a distributed file storage network, we would just be another application with an easily exploitable single point of failure.





